Micropython: a quick gc tour
In this post I will try to explain what I was able to gleam from looking over micropython's garbage collector, since the gc will most likely change over time this post is relevant as of the time of writing [1].
Also please note that I am neither an authority on micropython nor garbage collectors, I just enjoy working out how language implementations tick and micropython's gc seemed particularly well suited to picking apart over an evening.
Elevator summary
Micropython uses a simple mark-and-sweep ('stop the world') garbage collector; at runtime it is initialised and is given a range of memory to rule over, micropython has a simple 'allocation table' scheme for marking which parts of it's heap are in use, garbage collection is left up to implementations (ports to a platform) and is only triggered on allocation if there is insufficient remaining free memory to satisfy the request.
Magic numbers
Sadly there are a bunch of constants which I think are worth knowing, so please bear with me.
The garbage collector source lives in micropython/py/gc.c.
For the sake of throwing concrete numbers around I am going to be primarily talking about the unix implementation (micropython/unix/ in the distribution),
and since my system is 64bit I will use a 64bit unix system as the example.
The following constants are fixed regardless of platform
BLOCKS_PER_ATB = 4
WORDS_PER_BLOCK = 4
The following is provided by the platform
# 64 bit unix system uses sizeof(unsigned long) = 8
# 32 bit unix system uses sizeof(int) = 4
BYTES_PER_WORD = 8
And the following constant is then derived from this
# BYTES_PER_BLOCK = WORDS_PER_BLOCK * BYTES_PER_WORD
BYTES_PER_BLOCK = 32
Our heap
Micropython leaves the heap size up to the platform,
which passes the heap to gc_init via start and end pointers
def gc_init(start, end):
...
a simple subtraction is all that is required to find out the length our our heap.
On my 64 bit unix system we can see the size of the heap by looking at micropython/unix/main.c:63:
# heap size in bytes
# long heap_size = 128*1024 * (sizeof(machine_uint_t) / 4);
heap_size = 262144
and then the allocation of the heap and the call to gc_init:
# char *heap = malloc(heap_size);
heap = allocate(heap_size)
gc_init(heap, heap + heap_size);
So our gcs view of the world is currently
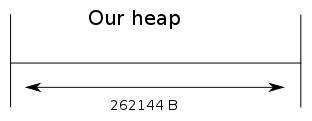
Initialisation
Memory in micropython is managed in chunks of BYTES_PER_BLOCK (32 Bytes) called 'block(s)',
the state of each block can be one of 4 things:
# block is not currently allocated
AT_FREE = 0
# block is the first in an allocated sequence
AT_HEAD = 1
# block is allocated but is not the first in this sequence (it will be release when the matching HEAD is release)
AT_TAIL = 2
# special value used for marking during tracing
AT_MARK = 3
To record these states micropython uses an allocation table made up of 'Allocation Table Blocks' (henceforce 'ATB(s)'), each 8 bits in size.
As each block has 4 possible states this requires 2 bits per block to encode, so each ATB 'manages' 4 blocks in the pool.
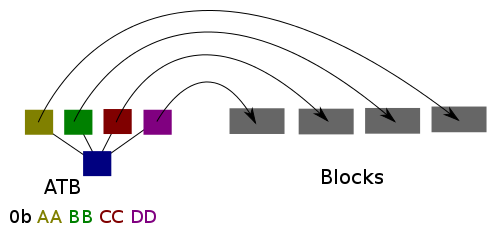
Micropython's gc divides it's heap into 2 areas [2], these 2 sections are called the 'Allocation Table' ('AT') and the 'Pool'.
The size of the allocation table is found via
total_byte_len = end - start
#alloc_table_byte_len = total_byte_len / (1 + BITS_PER_BYTE / 2 * BYTES_PER_BLOCK)
alloc_table_byte_len = 2032
since each ATB manages 4 blocks this means our gc now has quite a few blocks [3]
# num_blocks = alloc_table_byte_len * 4
num_blocks = 8218 blocks
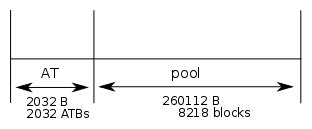
Allocation
Allocation is also quite simple and takes the number of bytes the caller would like
def gc_alloc(n_bytes):
...
gc_alloc must first convert this number of bytes into a number of blocks (as each block is 32 bytes)
gc_alloc then steps through the allocation table looking at each 2bit pair,
each representing the allocated-state for a block,
looking for a continuous sequence of n free blocks.
If gc_alloc is unsuccessful in it's search it then triggers a gc_collect and then tries again, if it is still unsuccessful then it gives up (return null).
If successful then we must mark each of the blocks as allocated, we also want all of this sequence to be treated as one logical block (they are allocated together and so should be freed together) so we mark the first block in the sequence as a head and the remaining blocks as tails
For example consider a call of gc_alloc(5) where our allocation table looks as follows:
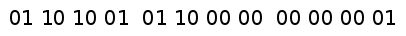
There is a space in there sufficient to satisfy the request:

So we mark the first block as a head (AT_HEAD) and the remaining 4 blocks as tails (AT_TAIL):
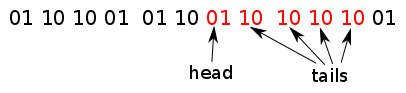
We then return a pointer to the first block in this sequence to the caller.
Ending notes
I think here is a good enough point to end on, Micropython's gc is very clean and simple and I recommend trying to dig through it yourself.
Of course there is more to cover as in this post I only went over initialisation and allocation, the remaining interesting part is collection which I hope to cover in a later post.
[1] https://github.com/micropython/micropython commit hash 95fd3528c12c0ae548fadc5e139e5e1dcf1da63e date Tue Jun 3 19:29:03 2014 +0100
[2] There would be a 3rd area for finalisers, but for the sake of brevity I am assuming they were disabled at compile time (MICROPY_ENABLE_FINALISER set to false).
[3] The astute reader may notice that this leaves 16 Bytes 'wasted' at the end of our pool (half a block)